
DUSt3R
Type: Paper
Notebook: Paper (https://www.notion.so/Paper-17de7e7bfd4c80e2bba1f0fe3a6c1131?pvs=21)
Motivation
The traditional SfM task (estimating the position of a 3D point given a sparse set of correspondences of multiple images and their image features) will divide it into sub-tasks, including the parameterization, matching, feature.
But the previous sub-tasks will feed the error into the next sub-task
So DUSt3R construct the network model end-to-end
Input & Output
Two images from two views
PointMap (HxWx3)
From the camera to the object, the position (x,y) records the 3D coordinate of the closest object, while it will be sheltered by the Translucent object
ConfidenceMap (HxW)
The true probability of each point in Pointmap
Network
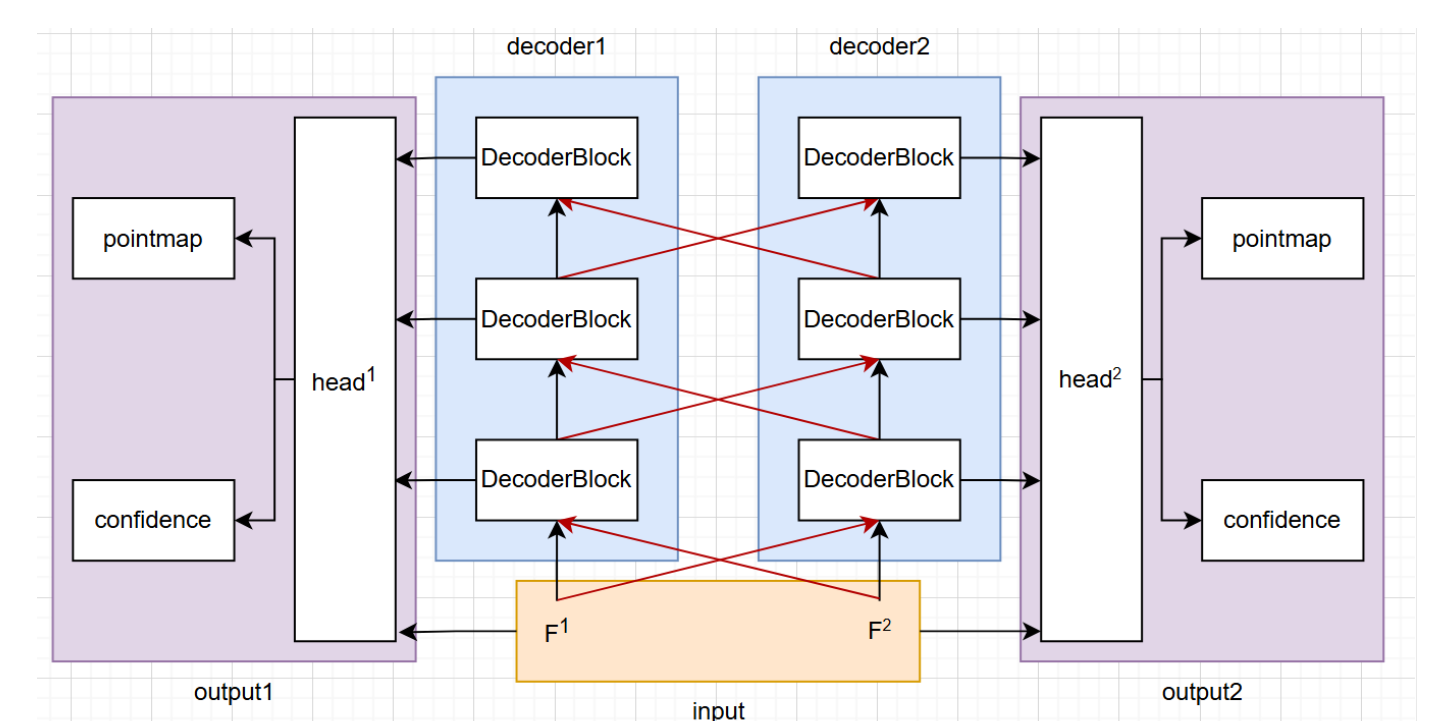
- Put the image into ViT encoder with shared weights to generate two tokens F1 and F2
- The Transformer Decoder will perform self-attention and then exchange info via cross-attention
- Output pointmaps and confidence maps.
Loss Function
3D Regression Loss
is the normalization factor, representing the average distance of the 3D points from the origin
It is the 3D distance error between the true points and PointMap points
Confidence-aware Loss
Multiplication of the confidence value and the 3D distance error, so that the confidence with larger distance will be lowered