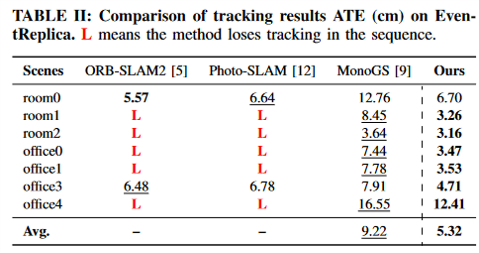
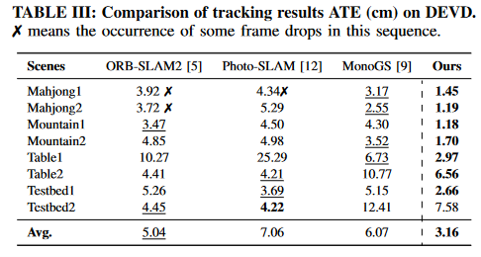
The first part is 3D Gaussian map representation, where each scene is represented by Gaussian points (including position, covariance matrix, opacity, and color parameters).
When a new scene is input, it continuously reduces the photometric, event, and depth loss for rendering, thereby optimizing the start and end poses of exposure.
Once the pose optimization converges in tracking, it checks whether to select it as a keyframe and updates the entire keyframe queue. After generating a new frame, it initializes some new 3D Gaussian point clouds and optimizes them jointly with various losses.
Blur-Aware Tracking
Camera Trajectory
T(η)=[Slerp(R0,Rτ,τη)0(1−τη)t0+τηtτ1]
Propose a temporal interpolation model for intra-exposure trajectory since we need precise camera pose for each event.
Photometric Loss
Blurred Image
Blurred image = Integral of sharp images during exposure time
I~(u)=∫0τI(T(η),u)dη≈K1k=0∑K−1I(T(ηk),u)
CRF
Learnable camera response function (CRF) bridges the HDR image and the LDR space by surpress the overexposure or underexposure.
Ek(u) is the ground truth event frame by aggerating the events in the exposure time τ
E^k(u)=log(B^(T(ηk),u))−log(B^(T(ηk−1),u)), where B^ is the predicted grayscale image from the Gaussian map. And the rendered event frame is the log difference of the two consecutive frames.
Loss Function
Here θ is the predefined threshold to trigger events, which is also the parameter to scale the event data and the brightness change.
LHE=K1n=0∑K−1Ek(u)=0∑θ⋅Ek(u)−E^k(u)1
The “No-Event” loss is used to penalize the event prediction when there are no events in the current frame to surpress the artifacts and accerate convergence.
LNE=K1n=0∑K−1Ek(u)=0∑E^k(u)1
Total event loss:
LE=LHE+λNELNE
Depth Loss
We choose the minimum depth value among the k bins:

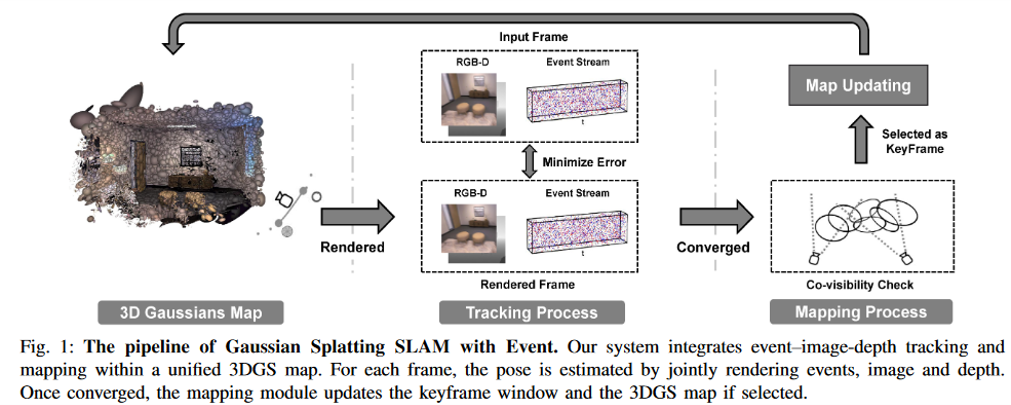 The first part is 3D Gaussian map representation, where each scene is represented by Gaussian points (including position, covariance matrix, opacity, and color parameters).
When a new scene is input, it continuously reduces the photometric, event, and depth loss for rendering, thereby optimizing the start and end poses of exposure.
Once the pose optimization converges in tracking, it checks whether to select it as a keyframe and updates the entire keyframe queue. After generating a new frame, it initializes some new 3D Gaussian point clouds and optimizes them jointly with various losses.
The first part is 3D Gaussian map representation, where each scene is represented by Gaussian points (including position, covariance matrix, opacity, and color parameters).
When a new scene is input, it continuously reduces the photometric, event, and depth loss for rendering, thereby optimizing the start and end poses of exposure.
Once the pose optimization converges in tracking, it checks whether to select it as a keyframe and updates the entire keyframe queue. After generating a new frame, it initializes some new 3D Gaussian point clouds and optimizes them jointly with various losses.