
Content
Event3R
Type: Paper
Venue: IROS 2026
Topic: Event-based feed-forward 3D reconstruction
Motivation
- DUSt3R-style methods show that feed-forward dense 3D reconstruction from images can be fast and globally consistent.
- However, RGB frames are still vulnerable to fast motion, motion blur, high dynamic range scenes, and low light.
- Event cameras are naturally robust in these conditions, but their data is asynchronous, sparse, and hard to feed into image-based reconstruction backbones.
- Event3R asks a direct question: can we reconstruct a globally aligned 3D pointmap from pure event streams in one feed-forward pass?
Input & Output
Input
- Two or more event stream segments
- Each segment is converted into a spatial-temporal voxel representation
Output
- Globally aligned 3D pointmaps
- Dense depth / pose-related geometry from event-only input
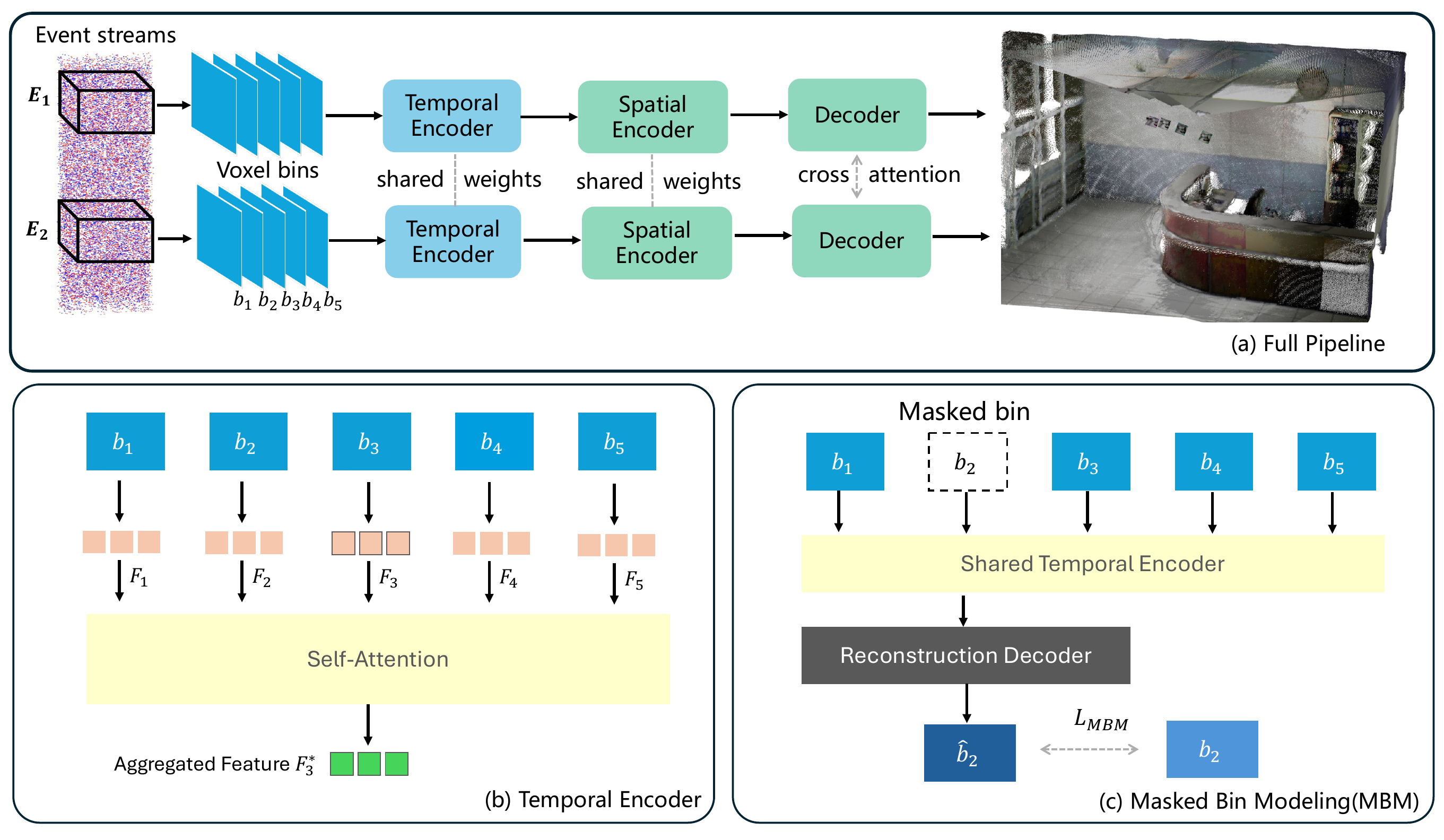
Pipeline
Event3R has three main stages:
- Event-to-voxel representation
- Temporal feature aggregation
- DUSt3R-style spatial reconstruction and decoding
The core is to bridge two worlds:
- event stream: asynchronous and temporally dense
- feed-forward 3D reconstruction: usually expects image-like synchronized inputs
Event-to-Voxel Representation
Each event is represented as:
where is the pixel location, is the timestamp, and is the polarity.
The event stream within a short temporal window is discretized into a voxel grid:
This keeps temporal information while making the input compatible with convolution / transformer style processing.
Temporal Encoder
The temporal encoder is the part I find most central. A naive solution would simply collapse all event bins into one image-like tensor. But that would throw away the ordering of motion.
Event3R instead processes each temporal bin as a structured frame and then performs attention across bins.
For a temporal bin:
For each spatial patch position, features across temporal bins form a sequence:
The center-bin feature is enhanced by attending to the whole temporal sequence:
This design is useful because the output pointmap is tied to a central temporal reference, while the surrounding bins provide motion and geometry cues.
Masked Bin Modeling
Event datasets with dense 3D labels are limited, so Event3R introduces Masked Bin Modeling (MBM).
The idea is similar in spirit to masked modeling:
- hide one or more temporal bins
- force the temporal encoder to reconstruct the missing bin
- learn better temporal aggregation before or during fine-tuning
This is especially suitable for event data because the temporal bins are not independent frames. Neighboring bins encode motion continuity.
Reconstruction Backbone
After temporal aggregation, Event3R uses a DUSt3R-style reconstruction backbone:
- spatial encoder extracts image-like geometric features
- decoder exchanges information across views with cross-attention
- final prediction is a globally consistent 3D pointmap
Compared with optimization-based event reconstruction, this feed-forward setting is much faster because it avoids per-scene iterative fitting.
Training Objectives
Event3R combines several objectives:
- supervised 3D reconstruction loss when labels are available
- MBM loss for temporal representation learning
- contrastive alignment to strengthen cross-view correspondence
- temporal consistency regularization to reduce unstable geometry across event segments
The important design point is that temporal learning is not only a preprocessing trick. It remains part of the reconstruction training objective.
Why It Works
- Event voxels convert asynchronous events into a learnable representation.
- Temporal attention keeps the motion structure instead of flattening time.
- MBM improves temporal feature learning when labeled event-depth-pose data is scarce.
- DUSt3R-style decoding gives globally aligned geometry without per-scene optimization.
Experiments
The paper evaluates Event3R on synthetic and real-world event benchmarks, including:
- dense 3D reconstruction
- depth estimation
- pose estimation
- challenging HDR / low-light conditions
The key result is that Event3R can reconstruct robust geometry from event-only input and generalize better under conditions where RGB-based reconstruction becomes unreliable.
Takeaways
Event3R is a step from local event reconstruction toward global event-based 3D reconstruction. The most important idea is not only “use events instead of RGB”, but how to make asynchronous temporal information understandable for a feed-forward 3D backbone.
For embodied perception and robotics, this is a useful direction: fast global geometry from event cameras could be valuable when robots move quickly or operate in difficult lighting.